






در عصر تحول دیجیتال، جایی که تأخیرهای میلیثانیهای مستقیماً به کاهش نرخ تبدیل (Conversion Rate) و ریزش کاربر منجر میشوند، کشینگ (Caching) دیگر یک راهکار ثانویه برای بهبود سرعت نیست؛ بلکه ستون فقرات مقیاسپذیری و بقای سیستمهای مدرن است. به عنوان یک معمار سیستم، نگاه ما به کشینگ باید از یک «حافظه موقت ساده» به یک «لایه استراتژیک مدیریت داده» تغییر کند که وظیفه آن کاهش بار محاسباتی و حذف گلوگاههای ناشی از فشار روی منابع دیسکی (RDBMS) است.
۱. مقدمه: ضرورت معماری مبتنی بر کشینگ
در عصر ترافیکهای انفجاری و حجم عظیم داده، کشینگ تنها ابزاری برای سریعتر کردن لود صفحه نیست، بلکه ابزاری برای حفظ پایداری (Resilience) است. وابستگی مستقیم میان سرعت پاسخدهی و تجربه کاربری (UX) به این معناست که هرگونه تأخیر در بازیابی داده، ریسک خروج کاربر از چرخه خرید یا تعامل را به همراه دارد. از منظر عملیاتی، کشینگ لایهای است که میان مصرفکننده و منبع اصلی (Origin) قرار میگیرد تا با توزیع هوشمندانه بار، از اشباع شدن پایگاه داده و زیرساختهای گرانقیمت جلوگیری کند.
——————————————————————————–
۲. کالبدشناسی لایههای کشینگ و پایداری معماری
تفکیک لایههای کشینگ نه تنها برای بهینهسازی پهنای باند، بلکه برای حذف «نقطه شکست واحد» (Single Point of Failure) حیاتی است. یک معماری چندلایه (Multi-layer Caching) تضمین میکند که در صورت سقوط یک لایه، سیستم همچنان قادر به سرویسدهی باشد.
- کش سمت کاربر (Browser Cache): ذخیرهسازی داراییهای استاتیک در کلاینت برای حذف کامل تأخیر شبکه در مراجعات بعدی.
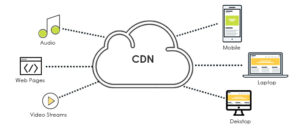
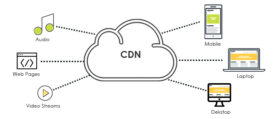
- کش شبکه و CDN: توزیع محتوا در لبه شبکه (Edge) جهت کاهش فاصله فیزیکی و RTT (زمان رفت و برگشت داده).
- کش پایگاه داده و اشیاء (Object Cache): ذخیره نتایج کوئریهای سنگین و اشیاء پردازش شده در حافظه RAM برای جلوگیری از محاسبات تکراری.
- کش سیستمعامل (CPU & Disk Cache): استفاده از لایههای L1 تا L3 در سطح سختافزار برای تسریع دسترسی به دستورالعملهای پایه.
تحلیل استراتژیک: استفاده همزمان از این لایهها ریسک شکست سیستم را با توزیع مسئولیتها کاهش میدهد. برای مثال، اگر لایه CDN دچار اختلال شود، وجود لایه Object Cache در سمت سرور مانع از هجوم مستقیم تمام درخواستها به دیتابیس اصلی میشود.
——————————————————————————–
۳. شاخصهای حیاتی عملکرد: فرمولها و مفاهیم کلیدی
در مهندسی عملکرد، «آنچه اندازهگیری نشود، بهینهسازی نمیشود». شاخص Cache Hit Ratio (CHR) قطبنمای ما در ارزیابی اثربخشی استراتژی کشینگ است.
فرمول محاسبه CHR: CHR = \frac{Hits}{Hits + Misses} \times 100
- Cache Hit: بازیابی موفق داده از لایه کش.
- Cache Miss: عدم وجود داده در کش که منجر به مراجعه پرهزینه به منبع اصلی (Origin) میشود.
ارزیابی عدد مطلوب: برخلاف باور عمومی، CHR بالا همیشه تنها هدف نیست. در حالی که برای فایلهای استاتیک در CDN عدد ۹۵٪ تا ۹۹٪ ایدهآل است، برای دادههای پویا و شخصیسازی شده، نرخ ۲۰٪ تا ۶۰٪ نیز یک موفقیت تجاری محسوب میشود. درک این تفاوت برای مدیریت انتظارات کسبوکار و جلوگیری از بیشبهینهسازی (Over-optimization) در مسیرهای داینامیک ضروری است.
——————————————————————————–
۴. نبرد غولها: Redis در مقابل Memcached
انتخاب بین این دو ابزار باید بر مبنای «مدیریت وضعیت در سیستمهای توزیعشده» (State Management in Distributed Systems) انجام شود.
| ویژگی | Memcached | Redis |
| ساختار داده | رشتههای ساده (Strings) | هش، لیست، ست، RedisJSON و… |
| پایداری (Persistence) | خیر (Volatile) | بله (Snapshotting و AOF) |
| معماری | چندرشتهای (Multi-threaded) | تکرشتهای با مدل Shared-nothing |
| قابلیتها | کشینگ ساده و سریع | پایگاه داده، صف پیام، Vector DB |
تحلیل معماری: مدل Shared-nothing در Redis کلید پایداری آن در ترافیکهای انفجاری (مانند بلکفرایدی در آمازون) است؛ زیرا با حذف قفلهای پیچیده (Locking) در دسترسیهای چندرشتهای، نرخ انتقال داده (Throughput) بسیار بالایی فراهم میکند. مورد مطالعاتی: پلتفرم HackerRank با استفاده از RedisJSON، وضعیت لحظهای اجرای کدها را با کمترین تأخیر به کاربران نمایش میدهد که نشاندهنده قدرت ساختارهای داده پیشرفته در Redis است.
——————————————————————————–
۵. استراتژیها و الگوهای پیادهسازی
انتخاب الگوی غلط مستقیماً منجر به ناهماهنگی دادهها (Data Inconsistency) میشود:
- Lazy Loading (Cache-Aside): رویکردی واکنشی که فقط دادههای درخواستی را ذخیره میکند (مقرون به صرفه از نظر حافظه).
- Write-Through: رویکردی فعال که همزمان با آپدیت دیتابیس، کش را بروز میکند (تضمین تازگی داده).
مدیریت انقضا (TTL): تعیین TTL باید بازتابی از نرخ تغییر داده باشد. تعادل میان «تازگی داده» و «بار سرور» در این لایه شکل میگیرد.
——————————————————————————–
۶. سیاستهای تخلیه (Eviction) و مدیریت حافظه پیشرفته
وقتی RAM (به عنوان منبعی گرانقیمت) پر میشود، استراتژی تخلیه تعیینکننده است:
- LRU (Least Recently Used): حذف دادههای قدیمیتر (مناسب برای اکثر سناریوها).
- LFU (Least Frequently Used): حذف دادههای کمتکرار.
- Active-Active Eviction: در پایگاههای داده توزیعشده (Active-Active)، فرآیند تخلیه از آستانه ۸۰٪ حافظه آغاز میشود تا فضای کافی برای انتشار (Propagation) تغییرات بین کلاسترها باقی بماند.
تکنولوژی Redis Flex: این رویکرد با جداسازی دادهها به دو دسته Hot Data (در DRAM) و Warm Data (روی SSD)، هزینههای زیرساخت را تا ۸۰٪ کاهش میدهد؛ در حالی که عملکردی مشابه حافظه خالص را برای دادههای پراستفاده حفظ میکند.
——————————————————————————–
۷. پیادهسازی عملی و هوشمندسازی دادهها
معماران ارشد از کش به عنوان یک «موتور پرسوجوی هوشمند» استفاده میکنند، نه فقط یک مخزن کلید-مقدار ساده.
نمونه Node.js (با ioredis):
const Redis = require('ioredis');
const redis = new Redis({ host: 'cache.internal' });
// استفاده از کش برای مدیریت وضعیت در مقیاس بالا
await redis.set('session:user:101', JSON.stringify(sessionData), 'EX', 1800);
نمونه C# (با StackExchange.Redis):
public static void Main(string[] args) {
ConnectionMultiplexer redis = ConnectionMultiplexer.Connect("localhost");
IDatabase db = redis.GetDatabase();
// ذخیرهسازی اتمیک با TTL
db.StringSet("product:stock:550", "42", TimeSpan.FromMinutes(10));
}
نکته استراتژیک: با استفاده از Redis Data Integration (RDI)، میتوانید کوئریهای خواندن را به طور کامل از RDBMS اصلی به Redis منتقل کنید (Offloading) تا عملکرد دیتابیس اصلی برای عملیات حیاتی حفظ شود.
——————————————————————————–
۸. کشینگ در عصر AI: Semantic Cache و Vector Databases
در دنیای AI، کشینگ وظیفه کاهش هزینههای فراخوانی LLMها را بر عهده دارد.
- Semantic Cache (مانند Redis LangCache): به جای ذخیره کلیدهای دقیق، معنای پرسشها را ذخیره میکند. اگر سوالی مشابه سوال قبلی پرسیده شود، پاسخ از کش بازگردانده میشود.
- Redis as a Vector Database: ذخیرهسازی Embeddings برای جستجوی شباهت معنایی با سرعت فوقالعاده بالا. استفاده از Redis Copilot در این مسیر، سرعت توسعه این قابلیتهای پیچیده را دوچندان میکند.
——————————————————————————–
۹. جمعبندی و چکلیست نهایی بهینهسازی
برای انتقال از یک «کش ساده» به یک «معماری داده هوشمند»، این ۵ اصل طلایی را مدنظر قرار دهید:
- تبدیل مخزن به موتور جستجو: از Redis Query Engine برای فیلتر کردن دادهها در لایه کش استفاده کنید تا منطق کد برنامه ساده شود.
- تعادل هزینه با Redis Flex: دادههای داغ را در DRAM و دادههای گرم را روی SSD مدیریت کنید.
- حذف فشار از دیتابیس: با RDI، بار خواندن را از پایگاه داده اصلی بردارید.
- پایداری توزیعشده: در سناریوهای Active-Active، آستانه ۸۰٪ تخلیه را در مانیتورینگ خود لحاظ کنید.
- توسعه استاندارد: از کتابخانههای رسمی و ابزارهایی مانند Redis Insight برای رصد وضعیت حافظه استفاده کنید.
چکلیست ارزیابی وضعیت:
- [ ] آیا CHR بر اساس نوع داده (استاتیک vs داینامیک) مانیتور میشود؟
- [ ] آیا برای کاهش هزینهها، استراتژی DRAM/SSD (Redis Flex) بررسی شده است؟
- [ ] آیا از Redis Query Engine برای حذف منطق پیچیده از سمت اپلیکیشن استفاده شده است؟
- [ ] آیا برای اپلیکیشنهای AI، لایه Semantic Cache پیادهسازی شده است؟
- [ ] آیا در صورت خرابی کش، لایههای بعدی (CDN/DB) برای تحمل بار آمادگی دارند؟