






در دنیایی که زیرساختهای دیجیتال بر پایههای ابر و سرور ابری بنا شدهاند، یک اختلال کوچک میتواند موجهای عظیمی در سراسر جهان ایجاد کند. این دقیقاً همان اتفاقی است که در ۲۰ اکتبر ۲۰۲۵ رخ داد؛ زمانی که قطعی گسترده در مرکز داده حیاتی US-EAST-1 آمازون (AWS)، بخش بزرگی از اینترنت را فلج کرد و درسهای مهمی در مورد اتکای کامل به یک ارائهدهنده به ما آموخت.
۲۰ اکتبر ۲۰۲۵: روزی که اینترنت از نفس افتاد
ساعتها اختلال جهانی؛ این خلاصهی اتفاقی بود که برای کاربران اپلیکیشنهای محبوبی مانند اسنپچت، ردیت و هزاران سرویس آنلاین دیگر رخ داد. کاربران در سراسر جهان با پیامهای خطا و عدم دسترسی مواجه شدند و گزارشها بهسرعت تأیید کردند که منشأ مشکل، بزرگترین ارائهدهنده خدمات ابری جهان، یعنی AWS و به طور خاص، منطقه US-EAST-1 آن است.
ریشهیابی مشکل: DNS و DynamoDB
بررسیهای اولیه نشان داد که ترکیبی از مشکلات در دو سرویس حیاتی AWS باعث این بحران شده است. اختلال در سیستم DNS (سرویس Route 53)، که مسئولیت ترجمه نام دامنه به آدرس IP را بر عهده دارد، در کنار مشکلات عملکردی در سرویس پایگاه داده NoSQL آمازون (DynamoDB)، یک شکست زنجیرهای (Cascading Failure) ایجاد کرد. این قطعی نشان داد که حتی مقاومترین زیرساختها نیز نقاط شکست واحد (Single Points of Failure) دارند.
تحلیل حادثه: ریسک اتکای کامل به یک ارائهدهنده
این حادثه بار دیگر زنگ خطری جدی را برای کسبوکارها به صدا درآورد: اتکای کامل به یک منطقه جغرافیایی یا حتی یک ارائهدهنده ابری واحد، ریسکپذیری بالایی دارد. اگرچه AWS زیرساخت قدرتمندی ارائه میدهد، اما متمرکز کردن تمام عملیات در یک منطقه (حتی اگر محبوبترین منطقه باشد) به معنای پذیرش ریسک یک قطعی کامل در صورت بروز حادثه است.
درسهای کلیدی این رویداد عبارتند از:
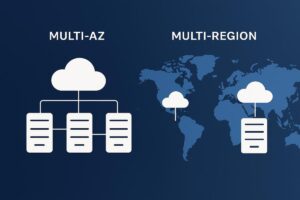
- اهمیت معماری چندمنطقهای (Multi-Region): توزیع بار کاری بین چندین مرکز داده جغرافیایی مجزا.
- استراتژی چندابری (Multi-Cloud): استفاده همزمان از چند ارائهدهنده ابری برای جلوگیری از وابستگی مطلق.
- تنظیمات Failover قوی: داشتن مکانیزمهای خودکار برای انتقال ترافیک به یک منطقه یا سرویس سالم در زمان بروز بحران.
- پشتیبانگیری محلی و خارج از سایت: اطمینان از دسترسی به دادهها حتی در صورت عدم دسترسی کامل به ارائهدهنده ابری.
کاهش ریسک با زیرساخت هوشمند: راهکار ابر دژ
در حالی که هیچ سیستمی ۱۰۰٪ مصون از خطا نیست، میتوان احتمال وقوع و تأثیر چنین قطعیهایی را به حداقل رساند. در ابر دژ، ما با درک عمیق این ریسکها، به مشتریان خود پلنهای متنوعی ارائه میدهیم که بر پایه زیرساختهای داخلی و توزیعشده بنا شدهاند. با انتخاب راهکارهای ابر دژ، شما میتوانید از مزایای یک معماری مقاومتر بهرهمند شوید و ریسکهای ناشی از اتکای به یک نقطه شکست واحد را به طور چشمگیری کاهش دهید.