





۱. مقدمه: از آزمایشگاه تا دنیای واقعی
تصور کنید یک سرآشپز فوقالعاده با دستور پختی بینظیر دارید. این سرآشپز میتواند در آشپزخانهی شخصی خود غذایی شگفتانگیز درست کند، اما بدون یک آشپزخانهی صنعتی مجهز، هرگز نمیتواند همان غذا را برای صدها مشتری سرو کند. MLOps دقیقاً همان «آشپزخانهی صنعتی» برای دانشمندان داده است.
در این مقاله، یک مثال را دنبال خواهیم کرد: سیستم تشخیص تقلب برای یک اپلیکیشن بانکی. تیم علم داده یک مدل چشمگیر ساخته است که در محیط توسعه و با استفاده از دادههای تاریخی و پاکسازیشده، میتواند ۹۵٪ از تراکنشهای متقلبانه را با هشدارهای غلط بسیار کم شناسایی کند. همه برای راهاندازی آن هیجانزده هستند.
هدف این مقاله، بررسی پنج تلهی رایج و حیاتی است که هنگام انتقال این مدل امیدوارکننده به یک محیط واقعی (Production) بدون یک چارچوب MLOps مناسب، رخ میدهند. این پنج مشکل عبارتند از: ۱. عدم سازگاری محیطها ۲. عدم تطابق عملکرد ۳. رانش داده (Data Drift) ۴. عدم قابلیت بازتولید ۵. نظارت ضعیف
با وجود هیجان اولیه برای موفقیت مدل، مسیر استقرار آن در دنیای واقعی پر از چالشهای پیشبینی نشده است. بیایید این چالشها را یک به یک بررسی کنیم.
۲. تله شماره ۱: مشکل “روی کامپیوتر من کار میکرد!” – عدم سازگاری محیطها
اولین مشکل بلافاصله پس از تلاش برای استقرار مدل آشکار میشود. مدل روی لپتاپ دانشمند داده عالی کار میکند، اما در سرورهای بانک با خطا مواجه میشود. علت اصلی، عدم سازگاری کامل بین محیط توسعه و محیط واقعی است.
| محیط توسعه (لپتاپ دانشمند داده) | محیط واقعی (سرورهای بانک) |
| زبان و ابزار: نوتبوکهای پایتون با کتابخانههای تخصصی یادگیری ماشین. | زبان و ابزار: اپلیکیشنهای جاوا که به دلیل پایداری، عملکرد و امنیت بالا انتخاب شدهاند.<br><br>علاوه بر این، تفاوتهای دیگری نیز وجود دارد:<ul><li>تفاوت در نسخههای کتابخانههای سیستمی (System Libraries)</li><li>تفاوت در وابستگیها (Dependencies)</li><li>تفاوت در منابع سختافزاری موجود مانند CPU و GPU</li></ul> |
این ناهماهنگی عواقب فوری و منفی به همراه دارد: تیم مهندسی مجبور میشود منطق مدل را به زبان جاوا بازنویسی کند. این فرآیند نه تنها زمانبر است، بلکه احتمال بروز خطا در آن بسیار بالاست.
نکتهی کلیدی در اینجا این است: وقتی محیطهای توسعه و تولید در زبان برنامهنویسی، کتابخانهها یا منابع سیستمی متفاوت باشند، رفتار مدل غیرقابلپیشبینی میشود. این امر منجر به بروز خطاها و افت عملکردی میشود که هرگز در طول توسعه مشاهده نشده بود. این بازنویسی اجباری و پر از خطا، نه تنها زمان را هدر داد، بلکه یک مشکل پنهان را آشکار کرد: عملکرد مدل در دنیای واقعی با معیارهای آزمایشگاهی کاملاً متفاوت بود.
۳. تله شماره ۲: عدم تطابق عملکرد – وقتی سرعت در آزمایشگاه به کندی در واقعیت تبدیل میشود
پس از بازنویسی مدل به جاوا و استقرار آن، مشکل جدیدی پدیدار میشود: مدل برای ارزیابی هر تراکنش ۳ ثانیه زمان نیاز دارد.
این تأخیر برای کسبوکار یک شکست کامل محسوب میشود. یک بانک که هزاران تراکنش در دقیقه را پردازش میکند، به زمان پاسخدهی در حد چند میلیثانیه نیاز دارد، نه چند ثانیه. تأخیر ۳ ثانیهای، تشخیص تقلب به صورت آنی را غیرممکن کرده و تجربهی کاربری مشتریان را مختل میکند.
درس مهم برای یادگیرنده این است: بدون آزمایش عملکرد در یک محیط شبیه به محیط واقعی قبل از استقرار، مدلی که در مرحلهی نمونهسازی سریع به نظر میرسد، میتواند تحت فشارهای دنیای واقعی به طور کامل شکست بخورد.
اکنون، از مشکلاتی که بلافاصله پس از راهاندازی ظاهر میشوند، به سراغ مشکلی ظریفتر میرویم که در طول زمان خود را نشان میدهد.
۴. تله شماره ۳: مشکل زمین لغزنده – پدیده “Data Drift”
فرض کنید یک ماه از استقرار مدل گذشته و همه چیز خوب به نظر میرسد. اما ناگهان، با وجود موفقیت اولیه، مدل شروع به نادیده گرفتن بسیاری از موارد تقلب میکند. چرا؟
این پدیده رانش داده (Data Drift) نامیده میشود. این اتفاق زمانی رخ میدهد که دادههای ورودی در دنیای واقعی شروع به تغییر میکنند و دیگر شبیه به دادههای آموزشی اولیه نیستند. در مثال ما، انواع جدیدی از تقلب ظهور کردهاند که در دادههای آموزشی اولیه و پاکسازیشده وجود نداشتند. برای مثال، مشتریان ناگهان شروع به انجام تعداد زیادی انتقال پول با مبالغ بالا به خارج از کشور در ساعات پایانی شب کردهاند.
درس اصلی این است: یک مدل یادگیری ماشین یک راهحل «یک بار بساز و فراموش کن» نیست. دقت آن به طور بنیادی به دادههایی که میبیند وابسته است و با تغییر رفتار در دنیای واقعی، عملکرد مدل میتواند به طور خاموش کاهش یابد.
مشکل افت عملکرد مدل، ما را به چالش بعدی میرساند: تلاش برای اصلاح آن.
۵. تله شماره ۴: مشکل دستور پخت گمشده – عدم قابلیت بازتولید (Reproducibility)
وقتی تیم تلاش میکند مدل را با نمونههای جدید تقلب بهروزرسانی کند، با مشکلی ناامیدکننده مواجه میشود: آنها نمیتوانند به همان نتایج خوب مدل اولیه دست پیدا کنند.
علت دقیق این مشکل این است که «هیچکس مستند نکرده بود که مدل اصلی دقیقاً چگونه ساخته شده است.» جزئیات ثبتنشدهای که باعث این مشکل شدهاند عبارتند از:
- دادههای دقیق استفادهشده: کدام بازهی زمانی از تراکنشهای مشتریان استفاده شده بود (مثلاً از ژانویه تا ژوئن).
- فیلترهای اعمالشده: چه مراحلی برای پاکسازی دادهها انجام شده بود (مثلاً حذف ورودیهای تکراری).
- تنظیمات مدل: چه پارامترهایی برای مدل انتخاب شده بود (مثلاً استفاده از آستانهای که هر انتقال بالای $8,000 را به عنوان ریسک بالا علامتگذاری میکرد).
اهمیت این شکست بسیار حیاتی است: بدون یک فرآیند قابل بازتولید، اشکالزدایی (debug)، ممیزی (audit) یا بهبود قابل اعتماد یک مدل غیرممکن است. هر تلاش برای بهروزرسانی آن به یک آزمایش کاملاً جدید و غیرقابلپیشبینی تبدیل میشود.
اینکه تمام مشکلات قبلی تنها پس از آسیبرساندن به مشتریان کشف شدند، خود نشانهی آخرین و شاید خطرناکترین تله بود: نبود هیچگونه دید و نظارتی بر سیستم.
۶. تله شماره ۵: مشکل پرواز کورکورانه – نظارت (Monitoring) ضعیف
تیم چگونه متوجه کاهش عملکرد مدل شد؟ از طریق شکایات مشتریان.
علت ریشهای این بود که هیچ سیستمی برای نظارت فعال و خودکار بر عملکرد مدل در محیط واقعی وجود نداشت. تیم هیچ داشبورد یا هشداری نداشت که نشان دهد دقت مدل در حال کاهش است.
نکتهی کلیدی این است: بدون نظارت مستمر، یک تیم در حال «پرواز کورکورانه» است. آنها تنها پس از آنکه مدل بر مشتریان و کسبوکار تأثیر منفی گذاشته است، از مشکلات باخبر میشوند. این وضعیت آنها را وارد یک چرخهی واکنشی و پراسترس برای حل مشکلات اضطراری میکند.
این پنج مشکل فلجکننده، نیاز به یک راهحل جامع را فریاد میزنند.
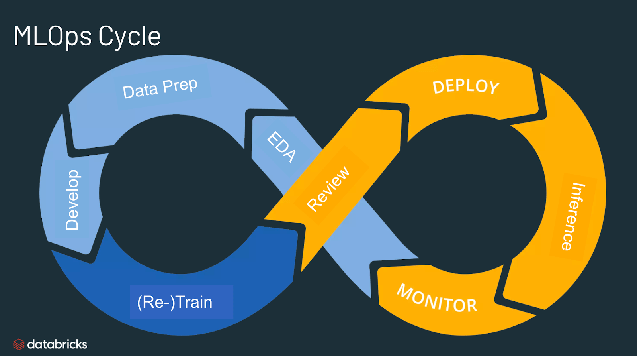
۷. راه حل: MLOps وارد میشود
MLOps (Machine Learning Operations) به عنوان یک راهحل ساختاریافته برای تمام مشکلات مورد بحث معرفی میشود.
به زبان ساده، MLOps به ما کمک میکند تا مدلها را از کامپیوتر دانشمند داده به محیط واقعی منتقل کرده و در آنجا به صورت قابل اعتماد اجرا کنیم. علاوه بر این، MLOps تضمین میکند که این مدلها در طول زمان به درستی به کار خود ادامه دهند. همانطور که «یک ماشین به نگهداری نیاز دارد، مدلهای یادگیری ماشین نیز به کسی نیاز دارند که مراقب آنها باشد.»
جدول زیر به طور خلاصه نشان میدهد که چگونه اصول MLOps هر یک از پنج تله را برطرف میکنند:
| تله (مشکل) | راه حل مفهومی MLOps |
| عدم سازگاری محیطها | استفاده از کانتینرها (مانند Docker) برای ایجاد محیطهای یکپارچه و قابل حمل. |
| عدم تطابق عملکرد | اجرای تستهای خودکار عملکرد در خطوط لوله CI/CD. |
| رانش داده (Data Drift) | نظارت مستمر بر دادههای ورودی. |
| عدم قابلیت بازتولید | ردیابی آزمایشها و نسخهبندی کد، دادهها و مدلها با ابزارهایی مانند MLflow. |
| نظارت ضعیف | داشبوردهای نظارت زنده (با ابزارهایی مانند Prometheus و Grafana) و سیستم هشدارهای آنی. |
با این راهحلها، تیمها میتوانند از بروز مشکلات جلوگیری کرده و سیستمهای هوشمند قابل اعتمادی بسازند.
۸. نتیجهگیری: از یک مدل امیدوارکننده تا یک سیستم قابل اعتماد
این مقاله نشان داد که MLOps یک افزودنی اختیاری نیست، بلکه یک رشتهی بنیادی است که برای ساخت سیستمهای هوش مصنوعی قوی و قابل استفاده در دنیای واقعی ضروری است.
سفر از یک مدل موفق در یک نوتبوک Jupyter به یک محصول ارزشمند در محیط واقعی، مملو از تلههایی است که بررسی کردیم. بدون یک رویکرد مهندسیشده، بهترین مدلها نیز در مرحلهی استقرار شکست میخورند.
در نهایت، MLOps همان پلی است که یادگیری ماشین آزمایشی را به سیستمهای هوش مصنوعی آماده برای تولید متصل میکند؛ سیستمهایی که کسبوکارها و مشتریان میتوانند به آنها اعتماد کنند.